.png) Get Started
Get Started

CSAT (Customer Satisfaction Score) is a metric used to measure a customer's satisfaction with a specific product, service, or interaction, typically expressed as a percentage of satisfied customers. In the most common 1-to-5 survey model, responses of 4 and 5 count as positive, so if 300 people respond positively out of 400 total responses, the CSAT is 75%.
That sounds simple on paper. It stops feeling simple when a community manager is staring at Discord threads, private support tickets, emoji reactions, and follow-up emails and trying to answer a basic question: are users happy, or are they just loud?
That's where most guides fall short. They explain the formula, then act like the work is done. In real support operations, especially across Discord, Slack, Telegram, email, and web chat, CSAT only becomes useful when a team understands what moment it measured, who answered, and what action should follow.
A billing complaint in email, a bug report in a private Discord thread, and a quick “where do I find this setting?” question in Slack should not be interpreted the same way. They may all produce a CSAT score. They do not carry the same meaning.
A user drops into your Discord help channel, gets an answer in three minutes, reacts with a thumbs-up, and disappears. Another user opens an email ticket about a refund, waits a day, gets a correct resolution, and still leaves annoyed. Both interactions can produce a CSAT response. They are not measuring the same thing.
CSAT measures how satisfied someone felt about a specific moment in the support experience. Usually that moment is a conversation, a resolution, or a completed request. It does not measure the full customer relationship, and it does not explain why the score was high or low on its own.
That narrow scope is what makes CSAT useful.
Support teams use CSAT because it ties feedback to an actual interaction instead of a vague impression of the brand. If a team sends the survey right after a ticket closes or a chat ends, they can trace satisfaction back to a queue, a workflow, a handoff, or an individual support motion.
That matters even more in community-led support. In Discord and Slack, one thread can mix troubleshooting, product education, moderation, and peer replies. A CSAT score helps separate "the conversation felt helpful" from "the overall community is healthy." Those are different questions, and they need different fixes.
Channel changes the meaning too. A high CSAT on live chat or Discord often reflects speed, tone, and clarity. A high CSAT on email usually reflects resolution quality, expectation setting, and whether the issue was closed. If a team compares those scores without context, they can misread what users are reacting to.
CSAT is best read as interaction feedback.
It can show whether the user felt heard, whether the answer arrived fast enough, whether the explanation made sense, and whether the outcome felt fair. In community spaces, it can also reflect something less obvious: whether the user felt comfortable asking for help in public.
It does not give a full read on loyalty, effort, or product sentiment. A customer can be happy with support and still dislike the product. A long-time advocate can hit one bad support exchange and give a low score. In practice, that is why strong teams do not treat CSAT as a summary of the whole customer experience.
The practical question is not "Is our CSAT good?" The practical question is "What experience did we just measure?"
Use that lens:
That is the primary job of CSAT. It gives teams a read on satisfaction at the interaction level, where support managers can implement changes. If scores drop in one channel, one queue, or one type of request, that usually points to a specific operational problem, not a brand problem.
A community manager closes ten help conversations in Discord before lunch. Five were quick wins. Two were messy but resolved. Three users never answered the survey. By afternoon, someone asks, “So what's our CSAT today?” The calculation is easy. The hard part is making sure everyone means the same thing by “satisfied.”
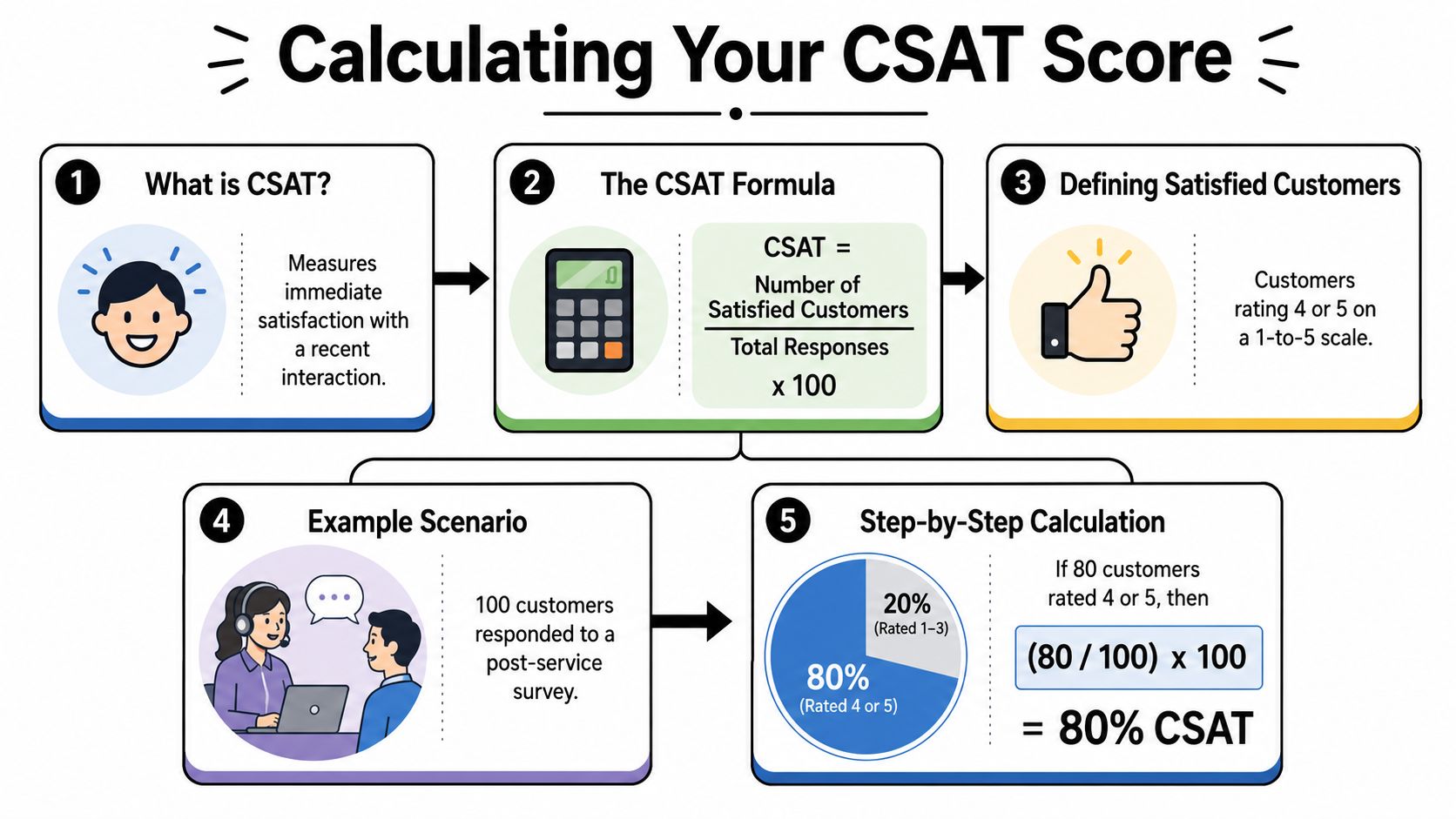
The common CSAT formula is:
CSAT = (Number of Satisfied Customers / Total Responses) × 100
That is the version many support teams use, and Geckoboard's CSAT guide lays it out clearly.
On a 1-to-5 survey, “satisfied customers” usually means people who selected 4 or 5. On a thumbs-up or yes-no survey, it means the positive response. What counts is consistency. If your Discord bot uses a binary survey but your email follow-up uses a 1-to-5 scale, you cannot compare those results as if they measure the same thing.
Use the formula in four steps:
If 40 people answered a post-support survey and 30 chose 4 or 5, the calculation is:
CSAT = (30 / 40) × 100 = 75%
That sounds simple because it is. The mistakes usually happen before the math starts.
A 75% CSAT in email support and a 75% CSAT in Discord can reflect very different experiences.
In email, users often expect a complete resolution, a clear explanation, and a reasonable response time. In Discord or Slack, satisfaction can be shaped by speed, tone, and whether the user felt comfortable asking in a public space. A fast reply in a thread may earn a high score even if the issue still needs a follow-up ticket. An email exchange may get a lower score for the same issue because the customer expected closure, not triage.
That is why teams should define the survey moment before they compare scores across channels. Measure after the same kind of interaction, or keep those benchmarks separate.
I see four common errors:
The last point matters more than many dashboards admit.
If you want a cleaner operating view, segment CSAT by channel, workflow, and conversation type first. Then compare trends inside those groups. Teams that want a broader framework for customer satisfaction metrics across support channels should do that before setting targets.
Say your team runs support in both Discord and email for a SaaS product.
It would be easy to conclude that Discord support is better. Sometimes that is true. Sometimes it just means Discord is handling simpler questions, while email is absorbing account issues, refunds, and edge cases.
This is the trade-off. CSAT is easiest to calculate when you flatten everything into one number. It becomes useful when you keep enough context to explain why that number moved.
That same discipline matters outside SaaS support too. Teams measuring customer satisfaction on Shopify run into the same issue when they mix post-purchase questions, shipping complaints, and product support into one score.
Pick one survey scale. Define which responses count as satisfied. Keep that definition stable. Then break results out by channel and interaction type so the score reflects the experience you delivered.
A community manager usually feels this choice in reporting first. Discord sentiment looks strong, email complaints are piling up, leadership asks for one number, and the team picks the wrong metric for the job.
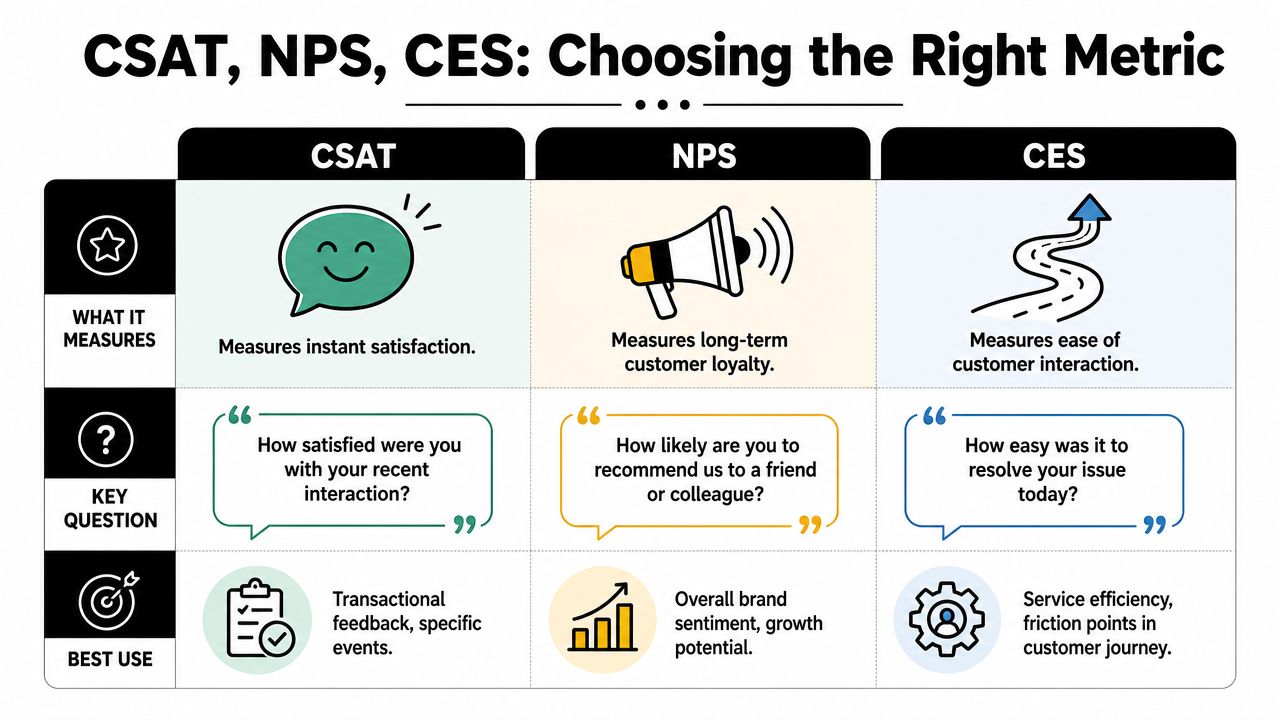
CSAT, NPS, and CES answer different operational questions. If you treat them as interchangeable, you get tidy dashboards and weak decisions.
MetricWhat It MeasuresQuestion TypeWhen to UseCSATSatisfaction with a specific interaction“How satisfied were you with your recent interaction?”After support, onboarding, or a defined eventNPSOverall loyalty and recommendation intent“How likely are you to recommend us to a friend or colleague?”Periodic relationship trackingCESEase or friction“How easy was it to resolve your issue today?”Service design and process improvement
Here is the practical cut.
CSAT works best when you need to know whether a reply, resolution, or moderator interaction felt helpful. CES is better when users are getting stuck, repeating themselves, or bouncing between channels. NPS is useful for understanding brand and relationship strength over time, but it is a weak tool for judging whether yesterday's support conversation went well.
Channel changes the meaning of all three. In Discord or Slack, speed, tone, and public visibility shape satisfaction fast. In email, users often care more about accuracy, completeness, and whether the issue was resolved. A high CSAT in community support can coexist with a mediocre CES if the team is friendly but the workflow still makes people work too hard.
A common mistake is using NPS to diagnose support quality. NPS is too broad for that. It can drop because of pricing, product reliability, or onboarding issues that have nothing to do with how the support team handled an interaction.
The reverse mistake happens too. Teams use CSAT as a stand-in for loyalty. That creates blind spots. A user can be satisfied with a fast refund and still be ready to churn.
CES is often the most underused metric in community-led support. It matters a lot in environments with handoffs, bot flows, channel routing, or long threads. If members keep asking follow-up questions because the path to resolution is unclear, CES usually exposes the problem faster than CSAT.
For teams building a broader measurement stack, this guide to customer satisfaction metrics across support channels is a useful reference point.
Use CSAT when the question is, “Did this interaction meet the user's expectations?”
Use CES when the question is, “How hard did we make this for the user?”
Use NPS when the question is, “How strong is the overall relationship with this customer or member?”
That distinction matters even more in omnichannel support. A Discord thread may earn strong CSAT because the mod was responsive and clear. The same user might give poor CES because they had to move from bot to public thread to private email to finish the case.
Ecommerce teams run into the same problem. The right metric depends on whether they are evaluating post-purchase confidence, support quality, or checkout friction. Helmsly covers that well in its guide to measuring customer satisfaction on Shopify.
If a Discord mod team wants to reduce repeat questions and messy handoffs, start with CES. If the team needs to know whether replies feel helpful, respectful, and clear, start with CSAT. If leadership wants one signal about long-term loyalty, use NPS, but do not expect it to explain support performance on its own.
A Discord mod closes twenty fast questions before lunch and gets glowing feedback. The same day, the email queue handles three billing disputes and one failed migration, and CSAT drops. Nothing about that report means the email team did worse work. It means the interactions were harder, the stakes were higher, and the channel changed what satisfaction measured.
“Good CSAT” only means something inside a clear context.
Dialpad points out in its CSAT glossary that benchmark ranges vary widely across sources. That is normal. Teams ask different survey questions, use different scales, and collect feedback at different moments. A community team asking “Was this reply helpful?” in Slack is measuring something narrower than an email team asking whether a case was resolved satisfactorily.
That is why broad benchmark ranges are useful as a loose reference, not a target you copy into a dashboard and manage against blindly.
CSAT from Discord, Slack, chat, and email should not be treated as interchangeable.
Public community channels tend to reward speed, clarity, and tone. Users often ask lighter questions there, and they can see the team responding in real time. Email usually collects slower, more complex, more sensitive work. Escalations, billing issues, security concerns, and edge-case bugs often land there. Those conversations can be handled well and still produce lower satisfaction because the underlying issue was painful.
The same logic applies inside one channel. A short “where do I find this setting?” thread and a two-day back-and-forth about a broken integration do not deserve the same benchmark.
I usually advise teams to stop asking, “What is a good overall CSAT?” Ask, “What is a healthy CSAT for this queue, with this type of issue, at this point in the journey?”
Useful CSAT benchmarks are segmented before they are judged.
This is also where support operations and content quality meet. If onboarding questions in Slack consistently score lower than expected, the issue may be weak docs, poor product messaging, or gaps in your bot flow. Teams that connect support to a knowledge base integration for community support usually get a cleaner view of whether dissatisfaction came from the reply itself or from missing self-serve help.
A useful CSAT target has three traits.
It reflects the reality of the queue. It is stable enough to track month over month. It gives the team something they can improve.
For example, a community support team may expect higher CSAT on simple product questions in Discord than on fraud reviews handled over email. That is sensible. What matters is whether each queue is performing well for its own mix of conversations, and whether negative feedback points to a fixable issue such as slow response time, unclear ownership, or weak documentation.
If your team wants to refine what you ask after each interaction, review these effective survey templates and adapt them by channel instead of sending the same CSAT prompt everywhere.
A good CSAT score is credible for the interaction, segmented by channel and issue type, and improving in a way the team can explain.
That is the standard I would use in 2026. Not one number across the whole support org. A score you can trust, compare fairly, and act on.
Collecting CSAT is easy. Collecting it in a way that stays useful is harder. The gap usually comes down to survey design, timing, and follow-through.
Infobip notes in its CSAT glossary that response bias, sampling bias, and the impact of timing and channel can all distort results. That matters even more in omnichannel and AI-assisted workflows, where the survey context changes often.
A strong CSAT survey should match the interaction. Don't force the same question everywhere.
Useful templates include:
Teams that want inspiration for wording can review effective survey templates and then adapt them to their own support environment.
The cleanest moment to ask is usually right after the interaction closes. If the survey arrives too late, memory fades. If it arrives too early, the customer may not know whether the issue is resolved.
For community-led support, the best trigger depends on the workflow:
What doesn't work well is blasting the same survey after every message. That trains users to ignore it.
A CSAT dashboard without a response process becomes a vanity layer. The useful move is to turn low scores into operational work.
A linked knowledge base helps here because recurring complaints often point to content gaps. Teams refining that part of the workflow can look at knowledge base integration for support operations.
The most useful CSAT programs don't ask more questions. They make better use of the answers they already get.
CSAT works because it stays narrow. It measures satisfaction with a specific interaction, not everything a customer feels about the company. That limitation is also its strength.
For support teams in Discord, Slack, Telegram, and email, the true value isn't the percentage on the dashboard. It's the pattern behind it. Which channel creates the most frustration. Which queue consistently earns weak feedback. Which handoff from AI to human leaves users confused. Which policies create friction even when agents respond well.
When teams segment the score properly and review the comments alongside the conversation, CSAT becomes operational. It shapes coaching, documentation, automation rules, escalation design, and product feedback. That's how a simple score starts influencing retention and service quality.
For a broader retention lens, this guide on how to improve customer retention is a useful next step.
A team doesn't need a perfect CSAT program to get value from it. It needs a consistent survey design, a clear interpretation model, and a habit of acting on weak signals before they become churn.
Mava helps community-driven companies run support across Discord, Telegram, Slack, and the web from one shared inbox, with AI agents, automations, analytics, and satisfaction tracking built in. For teams that want to measure CSAT in the same place they manage conversations, handoffs, and knowledge, it's a practical way to turn feedback into faster support and a better user experience.